

损失函数
损失函数是用来告诉我们当前分类器性能好坏的评价函数,是用于指导分类器权重调整的指导性函数,通过该函数可以知道该如何改进权重系数。

在图像识别中最常用的两个损失——多类别SVM损失(合页损失hinge loss)和交叉熵损失,分别对应多类别SVM分类器和Softmax分类器。



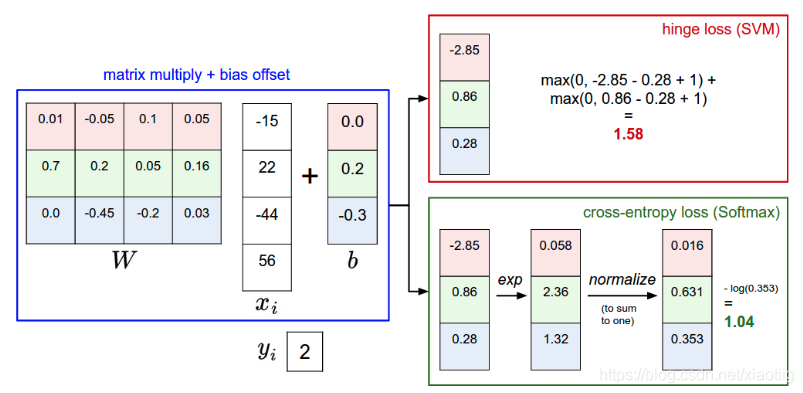
注意交叉熵是在softmax计算出概率后再用


就是两个值的差的绝对值
就是两个值的差的平方


首先明确一点,进入sigmoid或者softmax的值是多少维度,通过sigmoid或者softmax维度不变,比如sigmoid或者softmax输入前的维度是(256,256,10),通过它们以后输出的维度也是(256,256,10)。 跟给每个数加1的道理一样,只不过对每个数进行了函数变化

在深度学习中,一般来说,无论是用sigmoid和softmax,对应的都是交叉熵损失函数,一个对应
二分类和多分类都叫交叉熵损失函数,一个是sigmoid交叉熵损失函数,一个是softmax交叉熵损失函数
用的是sigmoid,就用binary_cross_entropy
用的是softmax,就用softmax_cross_entropy
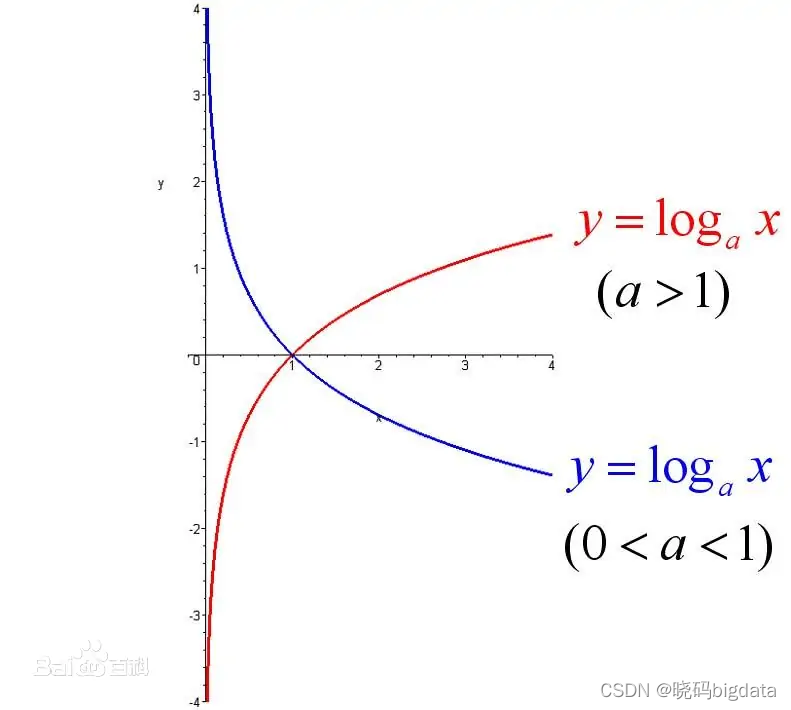
对数函数
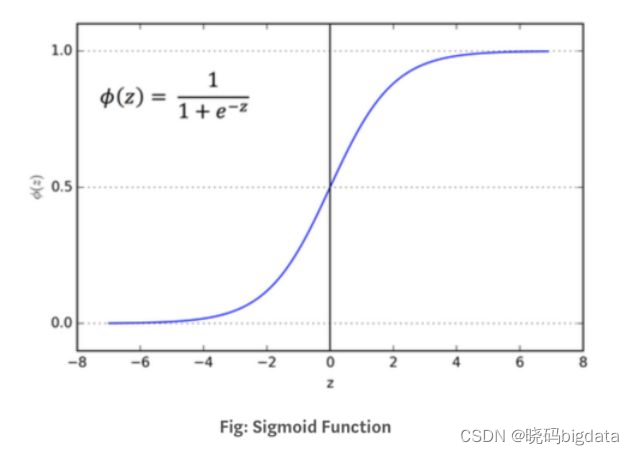
sigmoid函数
只为了判断这个值为0或为1
binary_cross_entropy
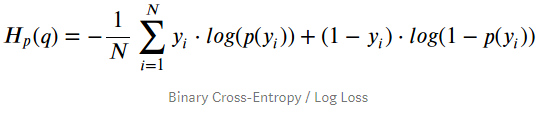
上面的yi表示真实标签,p(yi)表示经过sigmoid后的预测值。
举例:
举个例子,假设一个2分类问题,假如一个batch包含两个样本,第一个样本是类别0,第二个样本是类别1,那么标签要制成一维,形如:
y=[0,1 ],
模型预测输出也为一维,形如p=[ 0.2,0.6 ] #sigmoid的输出,这里一定要预先用sigmod处理,将预测结果限定在0~1之间。
对应的损失函数值计算:
L=( - 0*log(0.2) - (1 - 0)*log(1- 0.2) - log(0.6) - (1 -1)*log(1 - 0.6) ) / 2 = ( -log(0.8) - log(0.6) ) / 2
极端情况:
L = - 0*log(0.5) - (1 - 0)*log(1- 0.5)=-ln0.5 = ln2
softmax函数公式
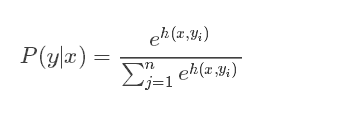

softmax计算步骤:

假设你的输入S=[1,2,3],那么经过softmax层后就会得到[0.09,0.24,0.67],这三个数字表示这个样本属于第1,2,3类的概率分别是0.09,0.24,0.67。
softmax_cross_entropy损失函数计算公式
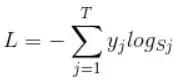
举例:
**举例1,**softmax计算二分类问题中用了softmax的输出,每个样本输出维2,用sigmoid的时候才为1
假设一个2分类问题,假如一个batch包含两个样本,那么标签要制成二维,
形如y=[ [1, 0],[0, 1] ],
模型预测输出也为二维,形如p=[ [0.8,0.2],[0.4,0.6] ] #(softmax的输出)
那么对应的损失L=( -log(0.8) - log(0.6) ) / 2
**举例2,**多分类,和上面例子计算过程一样
如果3分类问题某个样本预测的logits经过softmax或者sigmoid之后是(0.1, 0.8, 0.1)(这是softmax的结果,sigmoid不保证分量和为1),而labels的one hot形式是(0, 1, 0),那么该样本贡献的损失就是-(0ln0.1+1ln0.8+0*ln0.1)/3,batch loss就是一个batch的平均值。可以看出,全预测对,且正确项置信度为1,则loss为0,预测错误损失相当大。
语义分割中的 loss function 最全面汇总 - 知乎
https://zhuanlan.zhihu.com/p/101773544
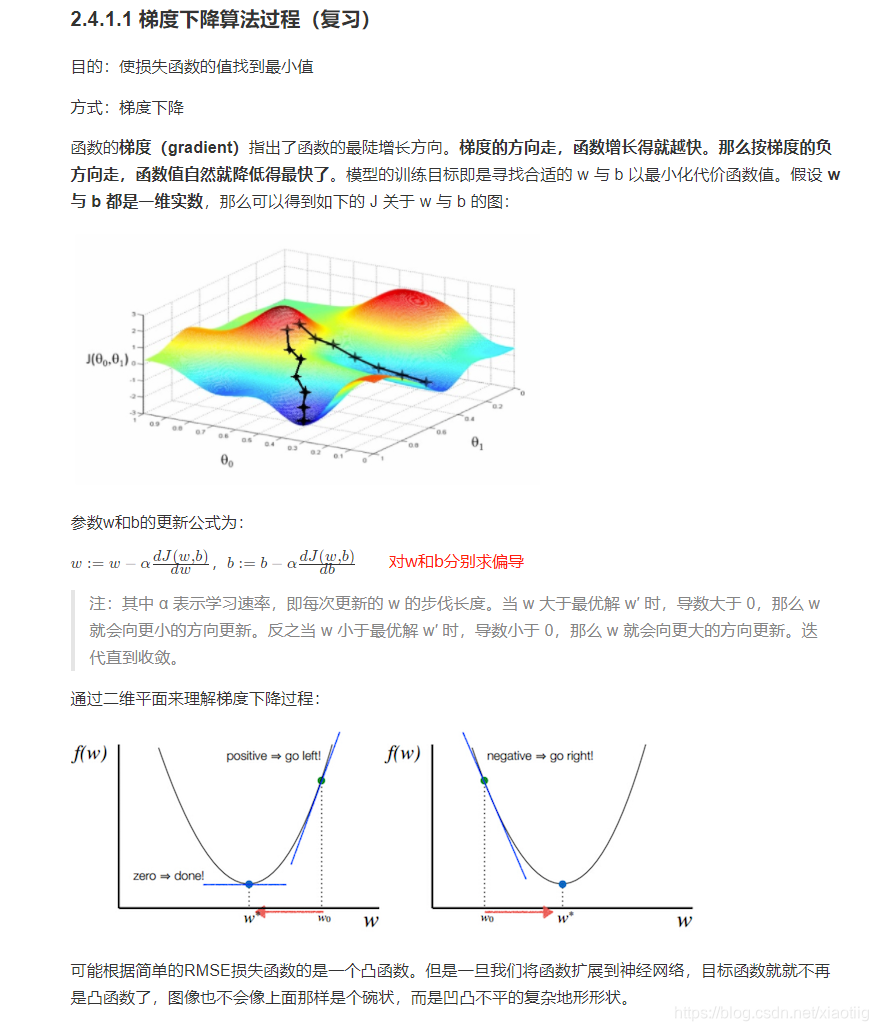
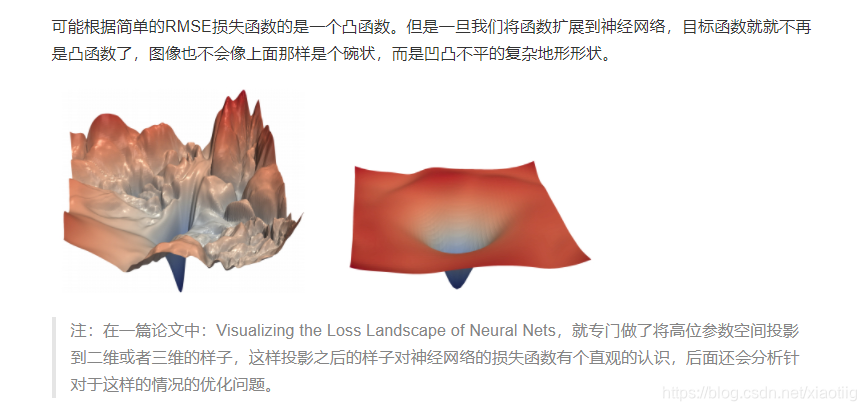
最优化是寻找能使得损失函数值最小化的参数W的过程
目的就是使损失函数最小
转换为更新参数W
方法就是求函数的梯度

3.2.1 导数与链式求导

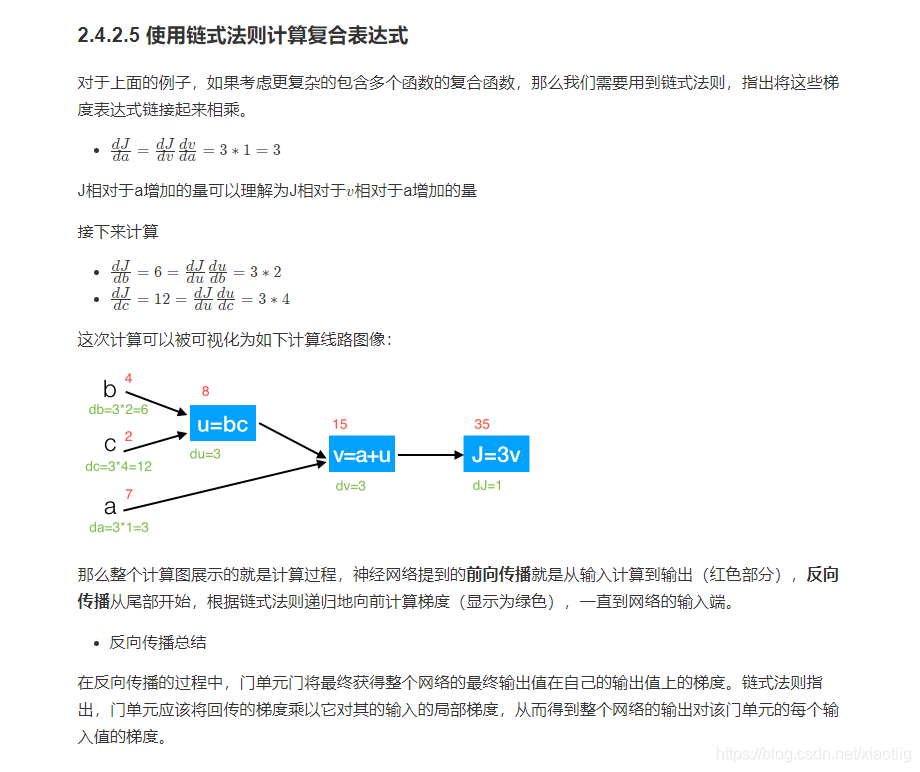

3.2.2 反向传播
反向传播就是利用链式求导法则进行反向计算
(1)案例:逻辑回归前向与反向传播简单计算
假设简单的模型为y =sigmoid(w1x1+w2x2+b), 我们在这里给几个随机的输入的值和权重,带入来计算一遍,其中在点x1,x2 = (-1 -2),目标值为1,假设给一个初始化w1,w2,b=(2, -3, -3),由于中间有sigmoid的计算过程,所以我们用代码来呈现刚才的过程。
我们可以看出来w1,w2,b是在这次更新是收到x的输入的影响梯度的计算的。



一共包括1个文件夹,(datasets文件夹存放了两个h5数据文件)
两个文件

data.py
single_unit_nn

